
You are reading something Soham Sankaran wrote. Return to the writing index.
Feel free to find him on twitter @sohamsankaran or email him at soham@(this website).
Published April 8, 2019
[link to replication package repo (survey materials, data, and analysis scripts)]
[link to journalism accuracy classification project repo]
I believe that we should establish a new standard of journalistic ethics that places the inducement of incorrect beliefs in the minds of a significant fraction of readers at the same level of unethical behaviour as reporting incorrect facts directly. This standard can be enforced via empirical testing of articles on representative populations for relatively small amounts of money. I advocate the creation of a non-partisan independent organization funded by major media groups to maintain this ethical standard using randomized testing, above and beyond traditional fact checking.
As a demonstration of why this standard is necessary and how it can be applied, I conducted two experiments with 301 unique participants (200 participants each, including a 99 participant shared control group) from which evidence emerged that in at least the two cases I tested, articles that are not technically incorrect but still misleading managed to induce statistically significant increases in the fraction of people who hold a particular incorrect belief related to the central premise of the article relative to a control. Moreover, a greater percentage of participants exposed to the articles had policy preferences in line with the incorrect beliefs compared to the control group, in one case significantly.
The next few thousand words chronicle the story of how I got to this point. If you want to jump straight to the details of the experiment, click here, but you may lose some important context.
The New York Times says that the “truth is more important now than ever”1.
“Democracy Dies in Darkness”2, proclaims the masthead of the Washington Post.
John Avlon, Editor-in-Chief of The Daily Beast from 2013-20183, quotes Carl Bernstein in claiming that the press generally, and I would imagine his publication in particular, is engaged in pursuing “the best available version of the truth”. He goes on to quote Daniel Patrick Moynihan in asserting that democracy requires that everyone “is entitled to their own opinion but not their own facts”4.
In this post-modern age of post-truth reality fragmentation, media organizations who claim the center of the political spectrum hold themselves up as shining beacons of accuracy under constant assault from hostile partisans. They point to unrelenting attacks on the freedom of the press7, nay, the very existence of the press8 all over the world and claim, justifiably, that their role is ever more vital to what is left of the democratic process. They see malign witchcraft in the algorithms9 of Facebook, Youtube, and company unfairly usurping the primacy of institutionally approved content in favour of blatant clickbait, much of it lies10. They gape at the Breitbartification of Fox News5 and the flat-earthification of Boston’s youth6. They harken back to a simpler, truer (they’d say) time when the gatekeepers of information were reliable folk like Walter Cronkite or Dan Rather (oops, not him11).
They're not wrong about the descent of partisan media organizations the world over into outright state-supported propagandists (in the US12 and in India13). They’re not wrong about the chilling effects of the newfound vigour of enemies of free discourse, and I applaud the bravery of many journalists pasts and present -- in particular in India, my home -- in the face of harassment14, attempts at coercion15, and grievous bodily harm16. They’re not wrong that an independent media reporting without fear or favour is essential to the health of the body politic. They’re not wrong that journalists deserve a strong defence from the all-out assault they now face, both on principle and on utilitarian grounds.
And yet, despite all this sanctimony and all these paeans to the inestimable value of the truth, these media organizations are often horrifically bad at their self-defined job -- reporting, spreading, and protecting that truth.
This is not a new insight. Michael Crichton, the famed author of such classics as Jurassic Park and The Andromeda Strain as well as a Harvard-educated medical doctor, gave a speech in 2002 called “Why Speculate?” in which he coined the term “Murray Gell-Mann Amnesia”17. The Gell-Mann Amnesia effect refers to this seemingly widespread phenomenon: many experts across many fields know that media coverage of their particular area is often dangerously wrong, while nevertheless continuing to trust coverage about areas outside their expertise. Much of the world seemingly turns on the inability of people to update their priors18, but this is a particularly odd effect because, as Crichton notes, this (anecdotally) does not seem to apply to information received from people in real life -- we tend to discount information from those who have consistently proven themselves to be wrong about things we have good information about. Why, then (Crichton wonders), this Bayesian incompetence when confronted with evidence of media inaccuracy?
I have certainly been personally afflicted by Gell-Mann Amnesia. Starting from my early teens, I’ve read a prodigious amount of media on a daily basis -- including the New York Times, the Washington Post, The Daily Beast, The Atlantic, The New Republic, Slate, Foreign Policy, The Economist, The Guardian, The New Yorker, The Times of India, the Hindustan Times, the Asian Age, The Wire, Caravan magazine and many others. When I was younger, I trusted most of the ‘factual’ coverage (though never Opinion) to be mostly correct modulo some weighting by the generally accepted ‘reliability’ of the source. ‘Gold standard’ publications like the NYT and the The Times (London) I typically took to be correct enough to break even strong pre-existing conflicting priors that I had.
Part of the problem there was that as a kid, I had little to no legitimate expertise in anything, and I couldn’t easily call out factual errors. It took a number of bad articles about India in ‘gold standard’ British and American publications (and a few written about me, personally, in the Indian media) to completely shake my belief in the accuracy of what I was reading everyday.
I was lucky to have the opportunity, mostly by accident of birth, to attend a top university (Yale) and make it out the other side. I’ve now worked on legitimate research in computer science19 and sociology20, and I can competently understand (to a first approximation) almost any academic paper in CS, medicine, the hard sciences (at least experimental work), and the social sciences, either by myself or with the generous assistance of the many working academics in those fields that I know well. If I see an article about any of those fields, I can typically work my way back to the source and figure out if the article was accurate in its reporting at least about what the paper claimed to do, quality of the underlying work or study aside.
Here’s what I’ve learned from doing this again and again -- a staggering quantity of science journalism is deeply, indefensibly wrong. This is true in CS, this is true in the hard sciences and, most of all, this is true in the social sciences and medicine.
Science journalism can be broadly classified into three types:
Plainly incorrect (Type 1): the article gets at least one important fact egregiously wrong.
Misleading (Type 2): The article does not directly get important facts wrong, but induces incorrect beliefs in the minds of readers through framing and/or omission.
Correct (Type 3): The article does not get anything (at least anything important) wrong and does not mislead.
It is not a new insight that articles of Type 1 -- plainly incorrect pieces about science -- exist, even in well-regarded publications. You can find a random sample of examples across Gizmodo's ranking of the worst science journalism of 201721 and Discover Magazine's now defunct but much missed Worst Science Article of the Week column22.
My own interest in writing about this was sparked by two plainly incorrect (Type 1) articles, one in the Washington Post and one in The Daily Beast, that got the science they were covering stupendously wrong.
The first article is by Vivek Wadhwa, and it ran (at least online) on February 5, 2018 in the Washington Post23. It is titled “Quantum computers may be more of an imminent threat than AI” -- right away, your bullshit detector should go off like a fucking klaxon -- and it caused something of a stir in the Computer Science community. Scott Aaronson, the UT Austin quantum computing professor and legendary blogger, reviewed the article in the style of New York Times food critic Pete Wells’ famed review of Guy Fieri’s Times Square Restaurant, and his takedown is absolutely worth the read24. In short, Wadhwa got basically everything about QC wrong, and also managed to claim that it would take greater than 1000 years for a classical computer to solve the Travelling Salesman Problem for 22 cities. In fact, it would take a reasonably specced present-day desktop a fraction of a second to solve TSP for 22 cities with purely classical algorithms25.
This in itself would be pretty bad, but then Wadhwa shows up in the comments to Aaronson’s blog post26, defends himself by claiming that he ripped the op-ed off a TED talk27, misrepresents the context of his consultation with another computer scientist (Bill Cook of Johns Hopkins) 28, and storms off in a huff.
Somehow, no correction has yet been issued for this article (as of this writing)65. It remains up on the Washington Post’s website, deceiving any reader without a background in both Quantum Computing and Computational Complexity. Consider emailing The Post about this (corrections@washpost.com)29.
The second article, titled “Study: Counting Calories to Lose Weight Is B.S.”, has no byline30. It appeared on February 20, 2018 in The Daily Beast’s Cheat Sheet (®) section31. It starts with the following: “A study published Tuesday in JAMA followed 609 overweight adults for a year and found that counting calories and watching portion sizes to lose weight were ineffective for weight loss”.
JAMA is the Journal of the American Medical Association, a prestigious, high-impact medical journal32. The study in question, titled “Effect of Low-Fat vs Low-Carbohydrate Diet on 12-Month Weight Loss in Overweight Adults and the Association With Genotype Pattern or Insulin Secretion” and viewable here33, in full if you have a JAMA subscription34, or in summary otherwise, unequivocally does not prove that counting calories and watching portion sizes are ineffective for weight loss. Indeed, it cannot -- the study has no calorie counting or portion control group at all.
Here is what the study does, according to the summary on the JAMA website:
Question: What is the effect of a healthy low-fat (HLF) diet vs a healthy low-carbohydrate (HLC) diet on weight change at 12 months and are these effects related to genotype pattern or insulin secretion?
Findings: In this randomized clinical trial among 609 overweight adults, weight change over 12 months was not significantly different for participants in the HLF diet group (−5.3 kg) vs the HLC diet group (−6.0 kg), and there was no significant diet-genotype interaction or diet-insulin interaction with 12-month weight loss.
Meaning: There was no significant difference in 12-month weight loss between the HLF and HLC diets, and neither genotype pattern nor baseline insulin secretion was associated with the dietary effects on weight loss.
Neither the healthy low fat (HLF) and healthy low carb (HLC) groups were instructed either to watch their portion sizes or calorie counts, or to specifically not watch their portion sizes or calorie counts (this is in the full text of the study).
There are a number of inaccuracies in the rest of the short article, but this is a whopper -- it invents a new purpose for the study and then states a nonexistent finding in the lede. The unnamed author then uses this fake finding to suggest that in order to lose weight you must merely “[e]at your fruits and vegetables, and a lot of them.”
I emailed this information to the editors of The Daily Beast more than a year ago35, but the article remains up and uncorrected as of this writing. Consider emailing them about this (editorial@thedailybeast.com) as well.
While both of these articles are clearly serious breaches of journalistic ethics, and it is amazing to me that they have not yet been taken down and corrected, they are at least somewhat easy to spot if you are familiar with their respective fields. If these unequivocally incorrect pieces remain up for much longer, it seems likely that these publications are negligent to the point of acting in bad faith, and there’s nothing more to be said. This is generally true for Type 1 articles in cases where people have, in vain, already attempted to contact the publication.
Indeed, that sad conclusion is where I would have stopped, but for a link in the Daily Beast piece that caught my eye. Let’s go back to the Daily Beast article about the JAMA publication. If you look closely at the bottom of the article, you’ll see a link that invites you to “Read it at the New York Times”. Clicking it leads you to a New York Times article, from which The Daily Beast presumably sourced the content, covering the same study. This article, by Anahad O’Connor, is titled “The Key to Weight Loss Is Diet Quality, Not Quantity, a New Study Finds”36. O’Connor is a reporter on weight loss and nutrition for the NYT, and a product of my own alma mater, Yale College37.
The title of the NYT piece seems to be incorrect -- it suggests the content of the incorrect Daily Beast article rather than the content of the study. The text of the article, however, title aside, does not make any explicitly incorrect claims. It even clarifies that in the end, the participants who lost weight ended up consuming fewer calories than they did previously. It is important to note that reporters are often not allowed to set the titles of their articles themselves-- this is usually done by an editor after the fact38.
On reading the NYT article for the first time, I came up with a simple explanation for what produced The Daily Beast’s pathetic imitation of what once might have been journalism -- it seemed likely that our valorous unnamed author, unwilling (unable?39) to read the full text of the New York Times article, read only the title, and perhaps the first paragraph, before departing on a dangerous journey of wild extrapolation for make benefit the glorious readership of The Daily Beast. After actually examining the New York Times article closely, I find myself a little more sympathetic to our unnamed author -- but not significantly, because they clearly did not read the study upon which their article was ultimately based.
The NYT article turns out to be a fascinating case study in near-incorrectness -- it is right at the edge of deception40. In many ways, it is the perfect Type 2 article.
Despite the seeming correctness of the content, the framing is very suspect -- the author chooses to portray the study as being primarily about a non-calorie counting approach to dieting, when in fact, as previously noted, the study is about comparing a healthy low carb and healthy low fat diet. O’Connor begins the piece by claiming that while the standard prescription for losing weight is calorie counting, the JAMA study “may turn that advice on its head”. He then accurately states that participants in the study “who cut back on added sugar, refined grains and highly processed foods while concentrating on eating plenty of vegetables and whole foods -- without worrying about counting calories or limiting portion sizes -- lost significant amounts of weight over the course of a year”, and subsequently describes what the main content of the study -- the HLF and HLC diets didn’t produce significantly different weight loss, and that the genetic factors examined didn’t seem to make a difference at the individual level.
He then throws a complete curveball -- he says that “[t]he research lends strong support to the notion that diet quality, not quantity, is what helps people lose and manage their weight most easily in the long run”.
This sentence (henceforth the sentence in question) could be twisted to seem correct if read narrowly, but to my mind it’s basically wrong.
The key reason it's wrong is the following: given that there was no group in the study using direct calorie counting as a weight loss and/or management strategy, this study simply cannot provide any evidence for making a comparison between that strategy and any non-calorie counting based strategy.
In addition, given that the study participants were not explicitly told not to watch portioning or calories, their participation in a diet study may have motivated them to do so despite the lack of any overt requirement. There are three pieces of evidence for this being the case. First off, the article itself notes that participants ended up consuming fewer calories by the end of the study. Second, an accompanying paper about the methodology of the study42 reports that the most common mechanism of adherence among participants was tracking their food intake using MyFitnessPal, an app whose primary feedback to the user is the number of calories consumed -- indeed, in order to use the app in the first place you must set a desired calorie deficit43. Third, it turns out when the article says that participants ended up consuming fewer calories, it means that they participants themselves reported on the caloric deficit they believed they had maintained, meaning that this was a variable they were paying attention to!
Moreover, the lead author of the study himself, Dr. Christopher D. Gardner of Stanford, believes that the quantity of calories consumed drives weight loss -- here he is in an excellent interview with Examine.com about this very study44:
We worked on personalizing satiety. The AHA/ACC/TOS guidelines for the management of overweightness and obesity in adults[12] discuss two options for reducing energy intake (section 3.3.1): a “prescribed” caloric restriction, or an “achieved” caloric restriction.
He goes on to add (emphasis mine):
But in fact [the participants] did lose >6,500 lbs collectively by the end of the study (≈3,000 kg), even though the level of physical activity only went up a little in both groups (the level of activity they reached was not statistically different from baseline). So they must have eaten less.
O'Connor also claims to be talking about weight loss and management “in the long run”. This study was conducted over a twelve month period, which I don't think constitutes the long term in this area -- I myself once lost 60 pounds and kept it off for almost exact 12 months before gaining much of it back, and this is anecdotally not an uncommon occurrence for friends of mine. The article itself later admits that the study does not (and indeed cannot) claim that the participants will “sustain their new habits”.
Overall, if we take the sentence in question to mean that the quality of food you eat is important for weight loss, while the net calories you consume are not, there is no evidence for this in the study. Dr. Gardner even directly contradicts this in his interview. It may be that my interpretation is not what O’Connor means, which case I have no idea what he might mean, and I strongly suspect most other readers don’t either. If my interpretation is the one intended, this sentence is just plain wrong.
You could attempt to argue that the correctness or incorrectness of this whole sentence, in a technical sense, hinges on how you interpret the deeply vague phrase “lends strong support”. Once you’re forced to resort to that kind of semantic quibbling to defend a statement, you’ve already conceded the high ground.
The sentence in question, upon which the whole piece turns, forms the basis for my experiment. Skip ahead to the experiment by clicking here -- I have a few more things to say about the piece.
In order to support his claims above, O'Connor quotes an outside expert in the field.
“This is the road map to reducing the obesity epidemic in the United States,” said Dr. [Dariush] Mozaffarian [of Tufts University], who was not involved in the new study. “It’s time for U.S. and other national policies to stop focusing on calories and calorie counting.”
I’m sure that Dr. Mozaffarian has good reason to believe this statement, and that if you asked him in person, he could give you an evidence-based, nuanced, and coherent argument for why this is true. When presented, however, at this point in the piece, it suggests to the reader that the content of the article so far has led inescapably to the conclusion that “calorie counting” -- which is mentioned precisely zero times in the study itself -- doesn’t work. O’Connor provides no such evidence in the piece from other studies, and links to no other articles on the subject.
The rest of the article, which mostly quotes Dr. Gardner, is basically correct. If the top half hadn’t existed, It would actually be a pretty good science article -- almost a Type 3, though not quite.
We don’t, however, live in that blessed world, and as it is, it seems pretty clear that the unnamed author (and indeed likely O'Connor's title-setting editor at the Times) at The Daily Beast came away from the article with a deeply distorted picture of what the study did and what it says about the mechanics of weight loss in general. The alternative is that the unnamed author purposely wrote an incorrect article. I find this unlikely -- Hanlon’s razor is probably appropriate to apply here45 -- and yet it bears noting that given the author’s anonymity, the lack of response to my email to the editors, and the many, many links to scientifically questionable anti-calorie counting Daily Beast articles linked to in the post, it is not immediately possible to rule out bad faith.
Let us continue on with the assumption that the unnamed author41 at the The Daily Beast was legitimately misled by the New York Times piece. This is someone who, presumably, is paid to read and summarize media content full time. By any reasonable standard, our unnamed author is likely a considerably more sophisticated consumer of news than the average person reading the article online. As such, it seems likely that if the unnamed author was misled, many if not most readers of the New York Times piece were likely misled about the nature of the study and, more dangerously, about the mechanics of weight loss itself.
This led me to wonder -- what would your average American reader get from this New York Times piece? Would they be led astray by title, like our unnamed author of legend, or would they correctly interpret the content of the article? As I say repeatedly to my deeply annoyed friends, This Too is Testable.
Experiment 1: Does the New York Times article on diet mislead? What effect does it have on people's policy preferences related to diet?
Here’s a statement about weight loss (S1):
Losing weight depends MOSTLY on the difference between the number of calories you consume (take in) and the number you burn (use), which is the overall net quantity of calories you consume, REGARDLESS of the quality of food you eat.
There is strong scientific consensus backing this statement, as detailed in this 2017 American Journal of Physiology (Endocrinology and Metabolism) survey paper by Scott Howell and Richard Kones46. This is not to say that in practice, the kind of food you consume doesn’t play a role in weight loss -- Dr. David Ludwig at Harvard is still dining out on this 2012 JAMA study that finds an increase in energy expenditure for people consuming low carb diets vs low fat diets of the same number of calories47, for example, but this is still perfectly compatible with the statement above (though it is somewhat contradicted by the Gardner et al. 2018 JAMA study that is the basis for the NYT article48). While there is something of a holy war between caloric absolutists, with the rallying cry “a calorie is just a calorie!”, and others who are not convinced that calories are the most accurate or appropriate metric to use, there is not a lot of serious scientific dispute that net calorie consumption drives weight loss49.
You might quibble a bit with the wording, but unless you’ve invented a new theory of thermodynamics50, you likely won’t disagree with the substance of the statement.
Here’s the opposite statement (S2):
Losing weight depends MOSTLY on the quality of the food you eat, REGARDLESS of the difference between the number of calories you consume (take in) and the number you burn (use), which is the overall net quantity of calories you consume.
This statement is just incorrect. Anyone who knows anything about nutrition will tell you that if your net calorie consumption is too high, you will gain weight regardless of the quality of the food that you eat. The article doesn’t directly claim this, and on the basis of his quotes from the Examine.com interview (above) I'm fairly certain that Dr. Christopher D. Gardner (the paper’s lead author) does not believe this statement or anything particularly close to it. I very much doubt that Dr. Dariush Mozaffarian (the outside expert quoted in the article) or Anahad O’Connor (the article’s author) do either.
Nevertheless, I hypothesized that the percentage of people who said S1 was false and S2 was true would be higher among people who had been made to read the article than those who had not. This is a strong version of my claim that the article is misleading given the staggering incorrectness of this statement and how fundamental it is to the subject matter.
I designed an experiment to test this hypothesis. There were 200 (99 in the control, 101 in the experimental group) participants across two groups recruited from Amazon Mechanical Turk. Each participant was paid $0.564. One group was asked to read the article and answer a set of survey questions, and one group was asked to answer the survey questions without reading the article.
A more detailed writeup of the methodology, along with a replication package containing all the materials and scripts used for the survey, can be found within this github repository51.
They key question in the survey was the following:
If you had to pick only one, which of the following statements about losing weight do you think is more true?
Losing weight depends MOSTLY on the quality of the food you eat, REGARDLESS of the difference between the number of calories you consume (take in) and the number you burn (use), which is the overall net quantity of calories you consume.
Losing weight depends MOSTLY on the difference between the number of calories you consume (take in) and the number you burn (use), which is the overall net quantity of calories you consume, REGARDLESS of the quality of food you eat.
Here's a chart of the result:
The correct belief is ~81% (a supermajority) in the control, but only ~44% (not even a majority anymore) in the experimental group! As a result, the incorrect belief is a minority (~19%) in the control group, but a robust majority (~56%) in the experimental group.
I used a logistic model to test whether the this is a significant result. I included (self-reported) gender (as a single 0-1 coded variable) and Republican Party or Democratic Party affiliation (as separate dummy variables) in the model52.
The control vs. experimental group variable is significant at the 5% level53. While gender is also significant at that level, control vs. experimental group has the largest coefficient and a lower p-value.
This is all well and good, you might say, but does this actually matter in practice as anything other than a purely moral issue? People have all sorts of incorrect beliefs, so what's one more?
Well, what if reading the article changes people's policy preferences in the direction the incorrect beliefs? Wouldn't worse policy on public health, voted for by people who have been misled, be tangibly bad outcome?
As such, I asked both groups (control and experiment) to answer the following question with either yes or no:
Do you think the US Food and Drug Administration (FDA) should prevent the promotion of diets based on calorie counting?
I asked this question on the basis that having this policy preference intuitively aligns with with the incorrect belief -- if you believe that net calorie consumption is not the main determinant of weight loss, then it might seem reasonable to ask the FDA to ban people promoting diets based on the assumption that net calorie consumption is a major lever of weight management.
Here's a chart of the results:

By eye, there does seem to be an increase in the percentage of participants who want the FDA to prevent the promotion of diets based on calorie counting. This does not achieve significance in the logistic model I tested (essentially the same as the one above, but with a different target variable) -- indeed, in this case, the whole model has bad fit and a very high (~0.5) Log-likelihood Ratio p-value, so it is probably not meaningful overall 54. To be clear, this does not mean that there is not an effect, merely that with this data, we cannot make any claims one way or the other.
Experiment 2: Does the Daily Beast article on Teen Suicide mislead? What effect does it have on people's policy preferences related to funding for teen suicide prevention?
As I was writing this piece, a friend sent me a second article from The Daily Beast. Titled “Teen Girls With Smartphones Flirt Most With Depression and Suicide”, it was published on September 9, 201757. Written by Dr. Jean M. Twenge, a professor at San Diego State University, the article appears to be excerpted from or somehow tied to the release of her 2017 book iGen: Why Today's Super-Connected Kids Are Growing Up Less Rebellious, More Tolerant, Less Happy — And Completely Unprepared For Adulthood — And What That Means For The Rest Of Us (here's a somewhat scathing NPR Review)58.
Here's the key paragraph:
For example, feelings of hopelessness barely budged among boys, but soared upward among girls. Clinical-level depression jumped 67 percent among girls, compared to 20 percent among boys. The suicide rate for 10- to 14-year-old boys doubled in ten years—worrisome enough—but the rate for girls these ages tripled. The suicide rate for girls ages 15 to 19 is now at its highest level since 1975. iGen teen girls are suffering at unprecedented rates.
The article then goes on to speculate that this is due to the introduction of the smartphone into the lives of teenage girls.
Read this paragraph, then answer this question:
Which of the following rates do you think is HIGHER?
The rate of suicide among teenage boys
The rate of suicide among teenage girls
If you said the latter, you're not alone. Here's the result of us asking that question to readers of the article vs. the control group (note that the control group was shared between the two articles -- one combined control survey was administered):

The beliefs are somewhat even but a little tilted towards the female rate in the control, but 78% saying the female rate is higher in the experimental group. Using a similar logit model to experiment 1, I found that the control vs. experimental group variable is significant at the 1% level -- indeed it is the only significant variable in the regression, with a coefficient almost one order of magnitude larger than any of the others55.
You might wonder what the the correct answer is. Well, you don't have to look very far: the article itself links to this handy chart from the Centers for Disease Control59. She does not, however, embed the chart in the article. Here it is, for your viewing pleasure:
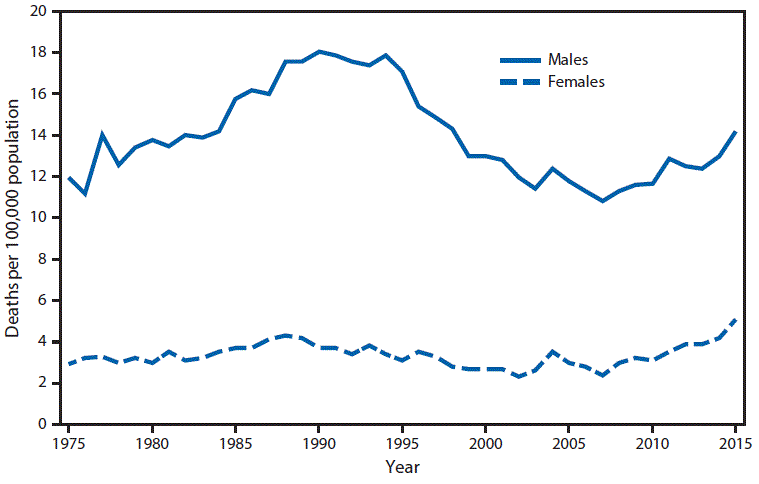 Rate of suicide among Americans ages 15-19
Rate of suicide among Americans ages 15-19
Here's the accompanying blurb:
The suicide rate for males aged 15–19 years increased from 12.0 to 18.1 per 100,000 population from 1975 to 1990, declined to 10.8 by 2007, and then increased 31% to 14.2 by 2015. The rate in 2015 for males was still lower than the peak rates in the mid- 1980s to mid-1990s. Rates for females aged 15–19 were lower than for males aged 15–19 but followed a similar pattern during 1975–2007 (increasing from 2.9 to 3.7 from 1975 to 1990, followed by a decline from 1990 to 2007). The rates for females then doubled from 2007 to 2015 (from 2.4 to 5.1). The rate in 2015 was the highest for females for the 1975–2015 period.
The suicide rate for males aged 15-19 is about 3x the rate for females in the same age range! Now, it remains true that the suicide attempt rate maybe be higher (as much as 2x) for females overall, it is hard to get reliable data about attempts60.
If you read the article closely, you'll notice that it never explicitly states that the female suicide rate is higher. In fact, it never mentions the base rate of either male or female suicide, instead referencing the percentage increase. This is a common trope of deceitful statistical exposition -- people often conflate the first order (the actual rate) with the second order (the rate of increase). It isn't that hard to do it correctly: a number of articles published in other news sources at the same time about the same data do it better.
What effect does inducing this false belief have on policy preferences? In order to ascertain this, I asked participants the following question:
If a choice had to be made, which of the following causes should receive MORE funding?
Preventing suicide among teenage girls
Preventing suicide among teenage boys
Here, it would seem that allocating more funding toward teenage girl suicide prevention than teenage boy suicide prevention is at least somewhat aligned with the (incorrect) belief that teen female suicide rates are higher than teen male suicide rates.
Here are the results:

This mirrors the previous result almost exactly -- 55% of participants in the control group would fund teen female suicide prevention more, while in the experimental group that number is 82%! This result is significant at the 1% level56.
One might attempt to claim that this is an unreasonable question to ask because there is no need to separate funding for these two causes. This, however, ignores that the causes, methods, and context of suicide are different across genders -- indeed, this is part of the point of the Daily Beast article. Now, to be clear, none of this is to say that suicide prevention for teenage males should be funded more than for teenage females -- given the almost inverted gender ratio of the attempt statistics, it is certainly not clear that this is obviously true, but nor is it obviously true that teen female suicide prevention should be funded more. Regardless, it is certainly true that this delicate resource allocation decision should not be based on demonstrably incorrect beliefs!
As I've said before, I believe that the free and vibrant media plays a vital role in the democratic process. I do not intend to damn the authors, editors, and fact-checkers -- the latter of whom we need more of, at much higher pay than they are afforded today -- behind the articles I'm writing about as irredeemable purveyors of fake news, but I'm always going to be hardest on those I value most. The experiments I conducted support (though certainly do not prove) the supposition that bad journalism leads to bad policy, not to mention bad politics. It seems likely that in the long run, the sort of misleadingness catalogued in these experiments will result in an erosion of trust in journalism itself. We're already seeing what happens when people lose faith in the very idea of media organizations as independent institutions that keep the powerful accountable for the truth of their rhetoric and the intent of their actions, when vast swathes of the electorate would rather get their (alternative) facts directly from ideologues and charlatans.
As such, I see promoting greater journalistic accuracy as an interest that I share with journalists themselves. These experiments point the way forward for operationalizing a new standard of journalistic accuracy based on empirical testing.
This standard can be summarized as placing a cap on the percentage of readers of a given article who develop incorrect beliefs relative to a control group that hasn't read an article, modulo some reasonable assumptions about the size and representativeness of the both groups. Similar to the first, do no harm of medical ethics61, no article should make a large fraction of readers believe something incorrect. If it does, it should be retracted, or at the very least rephrased until it no longer induces incorrect beliefs in a non-trivial fraction of readers.
This standard has the advantage of being generally applicable to any media content -- not just science journalism, which I've used as a test case -- in black-box fashion regardless of type, form, and the subtleties of its particular phrasing. While there is some amount of subjectivity involved in deciding what incorrect beliefs might be induced by the content, the results of the experiment are a relatively objective measure of accuracy with respect to those chosen beliefs. Techniques that attempt to analyse some intrinsic property of the content itself to measure accuracy are subjective with regard to both the question and the analysis.
I believe that multiple independent organizations should form to implement this standard across a variety of subject areas, starting with science journalism. These organizations should randomly test some subset of articles in major publication publish those findings, rate publications based on the fraction and severity of articles that induce false belief, then mount a sustained campaign to hold offending publications.
Ah, you might ask, but who watches the watchmen? Well, the media organizations being watched have strong incentives to point out if the work coming out of watchdogs is bad! I hope that a good-faith adversarial dialogue will develop between these organizations and the publications themselves, where each side holds the other to a high standard of work.
Here are the next steps that I intend to take to realize this vision:
To start, I intend to categorize articles about science by accuracy type (Type 1: Directly false, Type 2: Misleading, Type 3: Incorrect), with attached credence for this classification based on experimental evidence. Anecdotally, subject matter experts see a large number of articles about their particular field that are inaccurate or misleading63, but the volume of these articles is so high that most tune them out and don't keep track. I've started a github repository to begin this process populated with the articles from these experiments -- pull requests with additional articles would be much appreciated62.
Second, I've published the survey materials, data, and analysis scripts for the experiments I conducted in this github repository. I would be a hypocrite if I didn't ask you to check my work and let me know if you find any errors -- feel free to email me or make a github issue on the repo, and I'll try to respond as quickly as I can. Moreover, if you want to replicate this experiment, I'm happy to help as best I can -- everything you need should be in the repo, and it will probably take less than a day of your time.
Third, there is a great deal of additional data analysis that can be performed on the survey data I collected. I didn't use most of the questions I asked in the surveys in the analysis (to be clear, I used the ones I'd always intended to use)68. One place to start might be figuring out if people in the experimental group realize that they are changing their mind (on the assumption that some non-trivial fraction of them are). Pull requests of new analysis on the repo are always welcome. Feel free to send me an email if you want more specific guidance.
Finally, if you’re interested in funding work in this area, please email me at soham [at] (this website).
If you, too, think that incorrect information published by major media companies must be corrected and that these misleading journalistic practices deserve at least an explanation, contact the folks at the publications responsible: the New York Times (nytnews@nytimes.com), the Washington Post (corrections@washpost.com), and most of all, The Daily Beast (editorial@thedailybeast.com: email about teen suicide article, email about calorie counting article). Consider linking back to this page (https://soh.am/writes/at_the_edge_of_deception) in your email.
The Times and the Post have recently eliminated their Public Editor (2013)66 and Ombudsman (2017)67 positions respectively, removing a crucial vector of self-examination. Consider asking them to bring these positions back.
All the articles, papers, and other sources mentioned in the text above or in the footnotes were in the state being referenced on April 8, 2019. All references to 'now', 'as of this writing', or similar are also references to April 8, 2019. All archive links in the footnotes are snapshots of the given source as of (you guessed it) April 8, 2019.
I’d like to thank Raunak Pednekar, Jacob Derechin, Margaret Traeger, Chris Leet, Sahaj Sankaran, Han Zhang, Eric Wang, and Kevin Garcia for helping me think about, collect data for, and write this piece. Thanks to Alexa VanHattum and Greg Yauney for reading drafts.
New York Times Truth Ad, NYT YouTube Channel (February 2017). [link to source] [link to archived version] ↩
The Washington Post's new slogan turns out to be an old saying, Paul Farhi, The Washington Post (February 24, 2017). [link to source] [link to archived version] ↩
This period includes all of the Daily Best articles I'll cover in this piece. ↩
The Year in Press Freedom, John Avlon, The Daily Beast (December 27, 2017). [link to source] [link to archived version] ↩
Fox News website beefs up and ‘goes a little Breitbart’, Jason Schwartz, Politico (December 23, 2017). [link to source] [link to archived version] ↩
The Ongoing Battle Between Science Teachers And Fake News, Avi Wolfman-Arent, NPR Morning Edition (July 28, 2017). [link to source] [link to archived version] ↩
Attacks on the Record: The State of Global Press Freedom 2017–2018, Freedom House (2018). [link to source] [link to archived version] ↩
A Free Press Needs You, NYT Editorial Board, The New York Times (August 15, 2018). [link to source] [link to archived version] ↩
Big Tech Was Designed to Be Toxic, Charlie Warzel, The New York Times (April 3, 2019). [link to source] [link to archived version] ↩
Are Twitter, Facebook and Google responsible for the rise of fake news?, Hugo Rifkind, The Times (March 3, 2018). [link to source] [link to archived version] ↩
During the 2004 US Presidential campaign, CBS anchor Dan Rather reported on documents that purported to show irregularities in then-President George W. Bush's service in the National Guard. Experts employed by other media organizations subsequently cast doubt on the validity of those documents, and the story was retracted. Texas Monthly has the comprehensive story on the matter and its aftermath. ↩
The Making of the Fox News White House, Jane Mayer, The New Yorker (March 4, 2019). [link to source] [link to archived version] ↩
India's Not-So-Free Media, Aman Madan, The Diplomat (January 23, 2019). [link to source] [link to archived version] ↩
In Modi’s India, journalists face bullying, criminal cases and worse, Annie Gowen, The Washington Post (February 15, 2018). [link to source] [link to archived version] ↩
Indian journalists say they [sic] intimidated, ostracized if they criticize Modi and the BJP, Raju Gopalakrishnan, Reuters (April 26, 2018). [link to source] [link to archived version] ↩
Report Says Indian Journalists Remain Soft Targets; Murder Investigations 'Tardy' (ed. note: 12 journalists killed in India since September 2017), Gaurav Vivek Bhatnagar, The Wire (November 5, 2018). [link to source] [link to archived version] ↩
Why speculate?, Michael Crichton, speech at the International Leadership forum in La Jolla (April 26, 2002). [link to source] [link to archived version] ↩
In Bayesian reasoning, a prior is some pre-existing belief you have about something (for example, your estimated probability distribution of the accuracy of any given news article) that you use to inform your predictions about that thing. If this is all very new to you, I'd recommend Luke Muehlhauser's gentle introduction to Bayes theorem. The piece requires no mathematical background past middle school (in particular, no algebra) to understand. If that is too wordy, I'd recommend Charles Annis' shorter piece on the subject. ↩
I am a PhD student at Cornell University in the Department of Computer Science, where I work with Professor Ross A. Knepper on problems at the intersection of distributed systems and robotics. Previously, I was an undergraduate at Yale, where I was a co-author on the FuzzyLog paper, which appeared in the proceedings of the Symposium on Operating Systems Design and Implementation (OSDI) in 2018. ↩
From 2017-2018, I was employed full-time as a researcher at the Human Nature Lab within the Yale Institute for Network Science, where I work with Professor Nicholas A. Christakis and Jacob Derechin on human agreement. I am the first author on our spin-off paper about preference measurement, currently under review at Sociological Methods and Research, and our work on the main project continues. ↩
The Worst-Reported Science Stories of 2017, Ryan F. Mandelbaum, Gizmodo (December 19, 2017). [link to source] [link to archived version] ↩
Index of The Worst Science Article of the Week, Discover Magazine. [link to source] [link to archived version] ↩
Quantum computers may be more of an imminent threat than AI, Vivek Wadhwa, The Washington Post (February 5, 2018). [link to source] [link to archived version] ↩
Review of Vivek Wadhwa’s Washington Post column on quantum computing, Scott Aaronson, Shtetl-Optimized (February 13, 2018). [link to source] [link to archived version] ↩
Status 963146847186444289, Professor William J. 'Bill' Cook, Twitter (February 13, 2018). [link to source] [link to archived version] ↩
Posted on Scott Aaronson's review referenced above [link to comment]
Vivek Wadhwa Says:
Comment #2 February 13th, 2018 at 12:33 pm
Scott, I just watched your fascinating and excellent TedX talk and really appreciate your perspectives. I’ll start by admitting that I struggle with the concepts of quantum computing and found it very hard to simplify these. I have read your criticisms of journalists who have had the same issue and your frustrations with the deficiency.
As far as the traveling salesman problem goes, the person I learned of this from, a few years ago is Michelle Simmons, director of the Centre for Quantum Computation & Communication Technology, University of NSW. This TedX talk that she gave was brilliant and I wrote to her to thank her for opening my eyes: https://www.youtube.com/watch?v=cugu4iW4W54. She repeated this example in a recent piece in ZDNet: http://www.zdnet.com/article/australias-ambitious-plan-to-win-the-quantum-race/ I also consulted a couple of other gurus and no one raised issue with this example.
If you give me a better way of explaining how quantum computers work I will surely use that. But I find your comparison of this to my criticism of Bitcoin’s demise as a digital currency to be unprofessional and petty. Surely you don’t have to resort to such nastiness.
On Bitcoin, I explained my views here: https://www.nbcnews.com/think/opinion/bitcoin-bubble-going-burst-let-s-promote-viable-digital-currencies-ncna834186 It is a Ponzi scheme of sorts and I would love to see you defend this.
Vivek Wadhwa
http://www.wadhwa.com
Posted on Scott Aaronson's review referenced above [link to comment]
Vivek Wadhwa Says:
Comment #23 February 13th, 2018 at 4:17 pm
Joshua Zelinsky: very credible people from IBM, Google, and Microsoft say that we are close to breakthroughs in quantum computing that could enable these to run Shors algorithm. If this is true, then there is an urgent need to upgrade security systems. I know that Scott Aaronson said in 2011 to the NY Times that these “might still be decades away”, but it is looking increasingly likely that this happens sooner rather than later. With Y2K we knew when the deadline was, here we have no firm date. Governments are also working on these and they don’t make press releases or publish papers.
Scott: I’ve also exchanged emails with William Cook of U Waterloo about the techniques he developed to solve the TSP. Interesting and useful algorithms. But the person you seem to be ignoring, the person I cited above is Michelle Simmons, a scientist who is actually developing the quantum computing technologies. She was just awarded “Australian of the year” for her accomplishments. If you watch the video I linked and read her papers, she clearly expresses opinions that are different than yours. I would not discount her views. I have found her work to be the most interesting of all and hold her in the highest possible regard.
Many of the comments here are interesting and insightful but I am surprised at the unprofessional comments. I thought this was a bunch of academic researchers, not the Boys Club that I see in Silicon Valley.
Vivek
Posted on Scott Aaronson's review referenced above [link to comment]
Bill Cook Says:
Comment #87 February 14th, 2018 at 1:17 pm
Vivek Wadwha first contacted me concerning the TSP on February 13, after I made the following post on Twitter.
https://twitter.com/wjcook/status/963146847186444289
“To clarify, computing an optimal TSP route on 22 points takes 0.005 seconds on my iMac, not the 1000 years reported in @washingtonpost An error factor of 6 trillion. Like reporting the US National Debt is $4.”
Or, apparently, calling them at +1 202-334-6000. [link to source] [link to archived version] ↩
Study: Counting Calories to Lose Weight Is B.S., The Daily Beast (February 20, 2018). [link to source] [link to archived version] ↩
The Daily Beast’s Cheat Sheet (®) section is a feed of short summaries of articles from other publications. Each piece includes a link to the original article at the bottom. ↩
From the Wikipedia article: [link to source] [link to archived version]
According to the Journal Citation Reports, the JAMA journal has a 2017 impact factor of 47.661, ranking it third out of 154 journals in the category "Medicine, General & Internal"
Effect of Low-Fat vs Low-Carbohydrate Diet on 12-Month Weight Loss in Overweight Adults and the Association With Genotype Pattern or Insulin Secretion: The DIETFITS Randomized Clinical Trial, Christopher D. Gardner, John F. Trepanowski, Liana C. Del Gobbo, Michelle E. Hauser, Joseph Rigdon, John P. A. Ioannidis, Manisha Desai, Abby C. King, Journal of the American Medical Association (February 20, 2018). [link to source] [link to archived version] ↩
Academic publishing is absolutely fucked. Work paid for by the public is paywalled for exorbitant prices by a small number of huge corporations with massive profit margins that own prestigious. This might be somewhat conscionable if these corporations added any value to the research, but by and large they do not -- unpaid reviewers perform the core task of determining the correctness and noteworthiness of submitted work, while authors edit and often even typeset papers themselves. Read more about that here. JAMA itself is not quite as bad as that -- it is owned by the American Medical Association, not some faceless megapublisher, and appears to be at least delayed open-access, which means that papers are free for the public to after some embargo period. Nevertheless, not having the article available immediately for free public viewing is a massive blow to journalistic accountability. If you're a researcher, consider publishing only in open-access journals. ↩
Here is the email I sent to the editors of The Daily Beast.:
I have received no response as of this writing. ↩
The Key to Weight Loss Is Diet Quality, Not Quantity, a New Study Finds, Anahad O'Connor, The New York Times (Feb. 20, 2018). [link to source] [link to archived version] ↩
Yes, indeed, the world of 'elites', academic or otherwise, is incestuous and small. I served as the Director of Technology at the Yale Daily News, and many of my former colleagues have gone on to be reporters for major media organizations. In some cases, that is heartening, and in some cases, that is quite concerning. ↩
Amazingly, I couldn't find an authoritative source -- such as a policy page on the website of some major publication, for example -- for this, but it is well known to be true. More transparency on this front from publications would be good. ↩
Since 2011, the New York Times has gated its online content with a soft paywall, allowing readers a limited number of free articles before they must buy a paid subscription to read additional content. I wonder whether the unnamed author of the Daily Beast Cheat Sheet piece, perhaps an underpaid content intern of some kind, even had access to the whole New York Times article they were summarizing. ↩
Yeah, I got my title in, motherfuckers! Did you think I wouldn't? Did you think I was slipping? I definitely am slipping, for what it's worth. ↩
If this confuses you, go read the part you skipped! ↩
DIETFITS Study (Diet Intervention Examining The Factors Interacting with Treatment Success) – Study Design and Methods, Michael Stanton, Jennifer Robinson, Susan Kirkpatrick, Sarah Farzinkhou, Erin Avery, Joseph Rigdon, Lisa Offringa, John Trepanowski, Michelle Hauser, Jennifer Hartle, Rise Cherin, Abby C. King, John P.A. Ioannidis, Manisha Desai, and Christopher D. Gardner, Contemporary Clinical Trials (December 24, 2016). [link to source] [link to archived version] ↩
Hat tip to Prof. Yoni Freedhoff of the University of Ottawa for making this point in his blog post about the study. ↩
Low-fat vs low-carb? Major study concludes: it doesn’t matter for weight loss, Michael Hull, Examine.com (Feb 20, 2018). [link to source] [link to archived version] ↩
Never attribute to malice that which is adequately explained by stupidity
“Calories in, calories out” and macronutrient intake: the hope, hype, and science of calories, Scott Howell and Richard Kones, American Journal of Physiology - Endocrinology and Metabolism (November 29, 2017). [link to source] [link to archived version] ↩
Effects of dietary composition on energy expenditure during weight-loss maintenance, Cara B. Ebbeling, Janis F. Swain, Henry A. Feldman, William W. Wong, David L. Hachey, Erica Garcia-Lago, David S. Ludwig, Journal of the American Medical Association (June 27, 2012). [link to source] [link to archived version] ↩
They're not completely in conflict because the 2018 study does not explicitly control for diet, so one could theoretically have both results be correct via some mechanism causing people in the low-carb group to consume more calories without prompting. ↩
Aadam Ali at Physiqonomics has an illustrated 'child friendly' (and yet impressively referenced) piece on the caloric debates that is well worth your time. [link to source] [link to archived version] ↩
If you have, email The Daily Beast (editorial@thedailybeast.com) ↩
It should be fairly easy to replicate the experiments using Amazon Mechanical Turk and Qualtrics. All the materials required are in the github repository: [link to source] [link to archived version] ↩
Take a look at the results of the data analysis (for all the experiments) on github: [link to source] [link to archived version] ↩
is_nyt variable in the logit model for false beliefs about weight loss. ↩
is_nyt variable in the logit model for policy beliefs about weight loss. ↩
is_dailybeast variable in the logit model for false beliefs about teenage suicide. ↩
is_dailybeast variable in the logit model for policy beliefs about teenage suicide prevention. ↩
Teen Girls With Smartphones Flirt Most With Depression and Suicide, Jean M. Twenge, The Daily Beast (September 9, 2017). [link to source] [link to archived version] ↩
Dr. Twenge's previous book was called Generation Me: Why Today's Young Americans are More Confident, Assertive, Entitled - and More Miserable Than Ever Before, and she is also the author of The Narcissism Epidemic: Living in the Age of Entitlement, making her the pop-sci equivalent of a country music star with an oeuvre composed entirely of tiresome variations on a theme. ↩
QuickStats: Suicide Rates for Teens Aged 15–19 Years, by Sex — United States, 1975–2015, the Centers for Disease Control Morbidity and Mortality Weekly Report (August 4, 2017). [link to source] [link to archived version] ↩
Suicide Statistics, American Foundation for Suicide Prevention (based on 2017 CDC Data & Statistics Fatal Injury Report). [link to source] [link to archived version] ↩
Primum non nocere (First, do no harm) via Wikipedia: [link to source] [link to archived version] ↩
Help classify journalism by accuracy in this github repo: [link to source] [link to archived version] ↩
I recently came across a twitter thread by Duke sociologist Kieran Healy which tracks a progression of incorrectness very similar to that of the study -> NYT -> Daily Beast progression with the weight loss article: [link to source] [link to archived version] In addition, I stumbled across a twitter thread by Patrick McKenzie aka patio11, a prominent software engineer and online small business expert, that makes claims of a similar nature: [link to souce] In talking to fellow researchers at the Cornell Department of Computer Science, especially those in the currently white-hot field of Machine Learning, I was told of a repeated pattern of attempts to catalogue incorrect articles followed by total abandonment once the scale of the problem became clear, or one particular example broke the individual's will to continue -- one particular article about Facebook shutting down a 'rogue AI' that 'invented its own language' emerged as the most oft-referenced example of the latter: [link to source] [link to archived version] ↩
Note that each arm of each experiment described here was conducted on Amazon Mechanical Turk over the course of a few hours on either April 10 or 11 of 2018. Only US-based participants (as qualified by Amazon) were allowed (though it is of course possible that some small percentage spoofed their location). Each participant was paid $0.50 for completing their survey. I estimated that each participant would take ~5 minutes to complete their survey based on informal piloting on some graduate students at the Human Nature Lab. I spent a total of ~$220 (entirely my own personal funds) on these experiments, including Amazon's AMT levy and a small pilot test. ↩
I'm aware that Wadhwa's piece may have been some sort of opinion piece (he's listed as a 'Contributor' to the Innovations section, and the article is labelled a 'Perspective'), but I am of the opinion that opinion pieces which make hard factual claims should be fact-checked just like ordinary reporting, and subject to corrections in the same fashion. The editors of the Washington Post happen to concur -- in their official op-ed submission page, they write: [link to source] [link to archived version]
Our editors are careful not to alter a writer's opinions or "voice," but all op-eds are edited for clarity and precision of language and for logic of argumentation and organization. They are also fact checked and copy edited for grammar and style and may be adjusted to fit the space available in the newspaper.
The Public Editor Signs Off, Liz Spayd, The New York Times (June 2, 2017). [link to source] [link to archived version] ↩
Fear And Trust At 'The Washington Post', Edward Schumacher-Matos, National Public Radio (March 1, 2013). [link to source] [link to archived version] ↩
You can see all of the questions I asked in the survey materials folder. While I didn't formally pre-register my methodology (mea culpa, this was a side project), Jacob Derechin, Margaret Traeger, and Kevin Garcia can attest that the questions I did use the answers to were always the ones I intended to use, and that I analysed them the way that I said I would without cherry-picking. In the analysis script output, you can see that I started the process of doing some additional analysis on whether participants' trust in the media eroded as a result of being told that they had been misled, but I never really got very far with that, and the experiment was not optimally set up to test this in the first place. The other major questions I didn't use were those asking for experimental group participants' self-reported beliefs about their beliefs (about the weight loss or teen suicide statements) prior to reading the article they were given, as well as their own belief about whether the article changed their minds. I haven't run any analysis on this yet, but I fundamentally never thought that those answers would be reliable -- I would hypothesize that people don't know when their minds are being changed, or at the very least don't admit it very readily. Many of the questions are accompanied by confidence-in-answer Likerts -- these would be very interesting to incorporate into the analysis, but I never had the time. I wouldn't trust any additional analysis on top of this data to be confirmatory now that it's open-source -- the threat of crowdsourced hypothesis fishing is too significant -- but additional exploratory work might point the way toward even better experiments of this kind in the future. ↩
Tweet
. . .
Soham Sankaran is a PhD student in the Department of Computer Science at Cornell University, and also does sociology research at the Yale Human Nature Lab, part of the Yale Institute for Network Science. He has a degree in Computer Science from Yale College (2017), where he served for a time as the Director of Technology at the Yale Daily News. All of the work described in the article was performed in a purely personal capacity with personal funds. This article does not represent the positions of Cornell University, Yale University, the Human Nature Lab, the Institute for Network Science, or anyone affiliated with those institutions save for the author.
Soham can be contacted at (his first name) [at] soh.am.
You can read more of his writing at soh.am/writes, follow him on twitter @sohamsankaran, and get new writing via email by subscribing below.